
Most businesses think SEO starts with keywords and content. In reality, search visibility starts much earlier.
Before Google can rank a page, before AI systems can cite your content, and before ChatGPT, Gemini, Perplexity, or AI Overviews can understand your website, your site has to be crawled.
That’s where website crawlers — and tools like Screaming Frog — become essential.
For years, website crawling lived mostly in the world of technical SEO. But as AI-powered search systems continue reshaping how content is discovered, crawled, and interpreted, understanding crawlability is becoming foundational digital infrastructure.
And few tools are more recognizable in that space than Screaming Frog.
What Is a Website Crawler?
A website crawler, sometimes called a spider or bot, is software that systematically visits webpages, follows links, and collects information about a website’s structure and content.
Search engines rely on crawlers constantly. Google uses Googlebot. Bing uses Bingbot. AI systems and SEO platforms use their own crawlers as well.
These systems move through websites page by page, gathering information such as:
- page titles
- headings
- internal links
- structured data
- images
- status codes
- canonical tags
- metadata
- rendered content
You can think of crawlers like digital librarians mapping the structure of the internet.
If your website is difficult to crawl, important pages may never be fully understood or indexed correctly. And increasingly, that impacts not only SEO rankings, but AI visibility as well.
How Search Engines Crawl Websites
Modern search engines follow a relatively consistent process:
1. URL Discovery
Search engines discover pages through internal links, backlinks, XML sitemaps, submitted URLs, and previous crawls.
2. Crawling
Bots request the page and analyze HTML, links, JavaScript rendering, metadata, and structured content.
3. Understanding Structure
Search engines evaluate internal linking, content hierarchy, crawl depth, page relationships, and entity relevance.
4. Indexing
If the page is considered valuable and accessible, it may be stored in the search engine’s index.
5. Re-Crawling
Search engines revisit websites continuously to detect new content, updates, redirects, deleted pages, and technical changes.
This entire process depends on crawlability. If a crawler cannot properly access or interpret your site, your visibility suffers.
What Is Screaming Frog?
Screaming Frog is one of the most widely used technical SEO crawling tools in the industry.
Originally developed by the UK-based agency Screaming Frog, the software became popular because it allowed SEOs and developers to crawl websites the way search engines do.
Instead of relying on third-party SEO databases, Screaming Frog crawls your actual website in real time. That distinction matters.
It gives technical marketers a direct look into crawlability, architecture, indexing signals, technical issues, internal linking, and rendering behavior.
For many SEO professionals, Screaming Frog became the industry-standard crawler for diagnosing technical SEO problems. And despite the rise of AI tools and cloud platforms, it remains one of the most trusted technical SEO applications available today.
What Screaming Frog Actually Does
Screaming Frog can crawl websites similarly to search engine bots and surface issues that are often invisible during normal browsing.
Common use cases include:
- finding broken links
- identifying redirect chains
- auditing metadata
- detecting duplicate content
- analyzing canonicals
- identifying orphan pages
- reviewing XML sitemaps
- checking robots.txt directives
- evaluating crawl depth
- auditing JavaScript rendering
- extracting structured data
- visualizing internal linking
For larger websites, this becomes incredibly valuable.
Many businesses unknowingly have important pages buried too deeply, broken internal architecture, indexation issues, duplicate URL structures, crawl traps, or rendering problems.
These technical problems can quietly suppress search visibility for months or years.
A Brief History of Website Crawlers
Website crawlers have existed since the early days of the internet. As search engines emerged in the 1990s, crawlers became essential for mapping and organizing the rapidly growing web.
Early crawlers were relatively simple. Over time, technical SEO tools evolved alongside search engines themselves.
Early Technical Crawling Tools
Some of the earliest SEO crawling tools focused on broken link detection, site structure analysis, and HTML validation. Tools like Xenu Link Sleuth became popular among technical marketers.
The Rise of Screaming Frog
Screaming Frog helped modernize technical crawling for SEO professionals. Its desktop-based approach made advanced crawl analysis accessible to agencies, consultants, in-house SEO teams, developers, and publishers.
As websites became more complex, tools like Screaming Frog became increasingly important.
Enterprise Crawling Platforms
Over time, larger platforms emerged, including Botify, Lumar, formerly DeepCrawl, and OnCrawl.
These tools expanded into cloud-scale crawling, log file analysis, enterprise indexing diagnostics, and JavaScript rendering analysis.
The AI Infrastructure Era
Today, website crawling is evolving again.
Developers increasingly combine Screaming Frog, Firecrawl, Puppeteer, Beautiful Soup, AI systems, MCP servers, and LLM workflows to automate technical analysis and build machine-readable infrastructure.
Traditional SEO crawling is now intersecting directly with AI systems and automation pipelines.
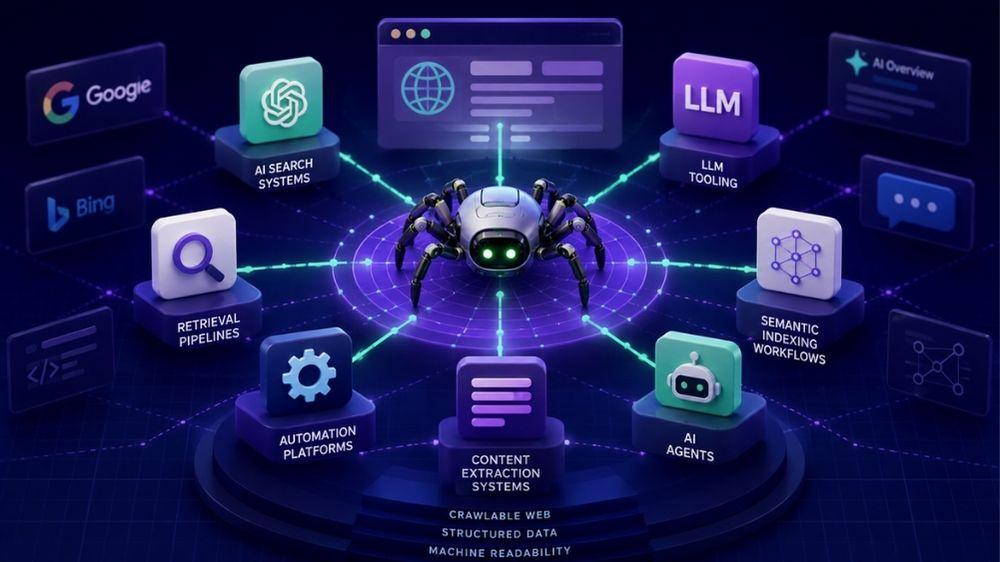
Crawlers Don’t Just Power Google Anymore
For years, website crawling was mostly discussed in the context of traditional search engines like Google and Bing. But today, crawling powers a much larger ecosystem.
Modern crawlers support AI search systems, retrieval pipelines, automation platforms, LLM tooling, content extraction systems, AI agents, and semantic indexing workflows.
In many ways, the modern web is increasingly optimized for machine readability. That’s one reason tools like Screaming Frog remain so relevant.
Why Crawling Matters More in the AI Era
One of the biggest misconceptions in SEO right now is the idea that AI somehow replaces technical SEO.
In reality, AI systems often increase the importance of crawlability and structured infrastructure.
AI search systems still rely heavily on crawlable pages, internal linking, semantic relationships, structured content, accessible HTML, metadata, and clean architecture.
If anything, machine-readable websites are becoming more important, not less.
Google’s recent AI search guidance reinforced this idea clearly. The message was not “find AI hacks.” The message was to build technically strong, crawlable, trustworthy websites.
That aligns closely with what we discussed in our article on Google’s evolving AI search recommendations: Google’s AI Search Guide Is a Warning: Stop Chasing GEO Hacks and Build Real Search Infrastructure.
AI search is not reducing the importance of technical SEO. It’s increasing the importance of machine-readable infrastructure.
How AI + MCP Workflows Are Changing Technical SEO
For years, technical SEO audits often resulted in massive spreadsheets that were difficult to prioritize. That’s changing quickly.
Modern workflows increasingly combine crawlers, AI assistants, automation systems, MCP servers, and LLM interfaces to analyze websites conversationally and automate technical diagnostics.
With the release of Screaming Frog v24 and MCP support, technical SEO workflows are becoming dramatically more powerful.
Instead of manually reviewing thousands of crawl rows, AI systems can now summarize crawl findings, identify patterns, cluster technical issues, explain problems conversationally, and assist with remediation workflows.
We recently documented our own experience using Screaming Frog v24 with MCP and Cursor here: Screaming Frog v24 MCP in Cursor: What We Learned Running a Real Crawl.
This shift is important. Technical SEO is gradually evolving from manual spreadsheet analysis into AI-assisted search infrastructure engineering.
Common Crawlability Problems We Find
Many websites have technical issues that quietly limit visibility.
Common examples include:
- broken internal links
- redirect chains
- orphan pages
- duplicate content
- crawl depth problems
- soft 404s
- blocked resources
- JavaScript rendering issues
- incorrect canonicals
- indexing conflicts
- weak internal linking
These issues often become more serious as websites grow larger.
In many cases, businesses are publishing good content that search engines and AI systems simply struggle to interpret correctly.

What Is Technical SEO?
Technical SEO focuses on improving the crawlability, accessibility, structure, and machine readability of a website.
Unlike content-focused SEO, technical SEO deals with site architecture, indexing, rendering, performance, structured data, crawl efficiency, internal linking, and URL structures.
Technical SEO helps search engines and AI systems understand websites more effectively. And increasingly, that impacts not just rankings, but discoverability across AI-powered search environments.
When Businesses Should Run a Crawl Audit
Not every website needs enterprise-level technical SEO.
Crawl audits become increasingly valuable when websites grow larger, multiple authors publish content, migrations occur, redesigns launch, indexing issues appear, AI visibility becomes important, or search traffic declines unexpectedly.
We commonly recommend crawl audits for ecommerce sites, publishers, SaaS companies, multi-location businesses, large content websites, and growing startups.
Many technical problems are difficult to identify without proper crawling tools.
The Future of SEO Is Machine Readability
The future of search is not just about publishing more content. It’s about helping machines understand your website clearly.
Search engines still rely on crawling. AI systems still rely on structured retrieval. Visibility still depends on accessibility and architecture.
Crawlers were always foundational to search. Now they’re becoming foundational to AI discovery as well.
Want Help Understanding Your Website’s Crawlability?
Whether you’re trying to improve SEO performance, diagnose indexing problems, or better understand how AI systems view your website, we can help.
Run a Self-Service AI Visibility Scan
Request a Professional Website Crawl Audit
We can perform a professional crawl analysis using tools like Screaming Frog, AI-assisted workflows, and technical SEO diagnostics to uncover crawlability and visibility issues.



